前言
上篇介绍了深度学习框架pytorch的安装以及神经网络的基本单元:感知机。本文将介绍全连接神经网络(FCNet)的结构和训练方法,全连接神经网络是一种典型的前馈网络。感知机解决不了非线性分类问题,但是多层神经元叠加在一起理论上可以拟合任意的非线性连续函数映射。
全连接网络
全连接网络是一种前馈网络,由输入层、输出层和若干个隐层组成。如下图所示,输入层由d个神经元组成,用于输入样本的各个特征值;网络可以存在若干个隐层,每个隐层的神经元个数也是不确定的;输出层由l个神经元组成,l就是最后要分类的类别数。因此神经网络由很多层构成。
神经元之间的连接方式为:同一层之间的神经元没有连接关系,每一层的神经元和下一层的所有神经元连接。每两个连接的神经元之间都有一个连接权重,这里记第i个神经元和下一层第j个神经元的权重为ωij。
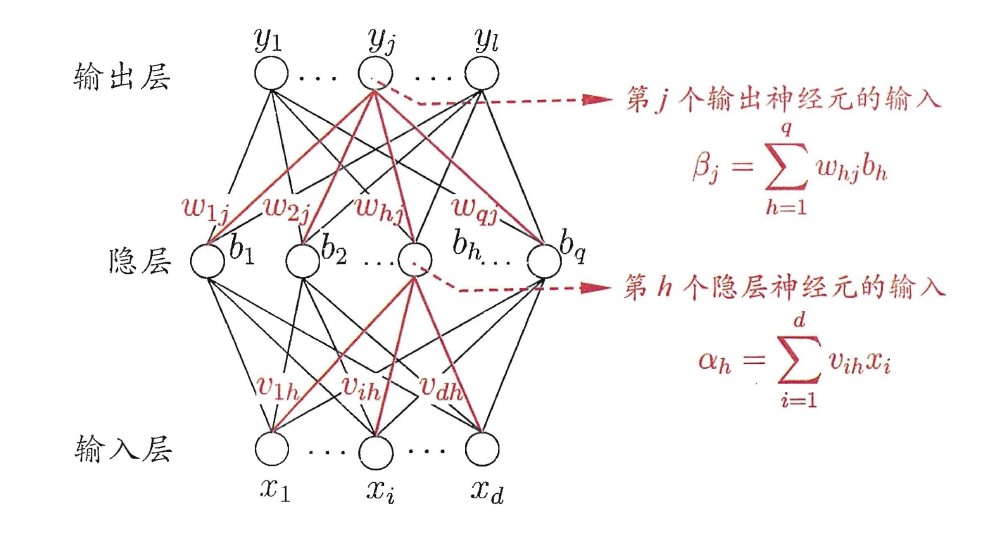
以上图中只有一个隐层的神经网络为例,隐层的第h个神经元的输入可以表示为:
αh=i=1∑dvihxi
其输出则是输入经过激活函数f作用在输入上,这里取激活函数为Sigmoid函数:
sigmoid(x)=1+e−x1
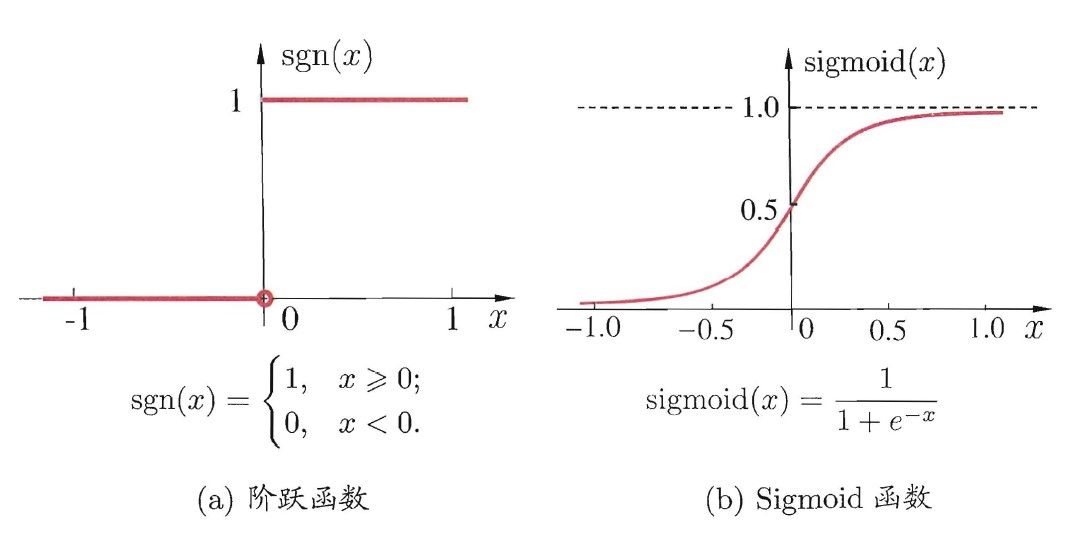
之前我们使用的是阶跃函数,Sigmoid也是一个非线性函数,它有一个很好的性质就是它的导数可以用自己本身来表示:
y′=y(1−y)
阶跃函数和Sigmoid的函数图如下:
这样全连接网络的输出计算也就是前向传播的过程为:首先通过输入层计算得到第一个隐层的输出,第i个神经元至第h个神经元的计算公式为:
output=f(i=1∑dvihxi)
然后通过第一个隐层计算下一个隐层的值,最后传播到输出层,最后得到神经网络的输出为:
y^=(y^1,y^2,...,y^l)
神经网络训练之BP算法
我们知道神经网络之所以能够具有很好的拟合能力,就是因为多个神经元之间的连接权重在起作用,那么对上面介绍的神经网络应该怎么训练呢?应该怎么找到最适合一个数据集分类的各个神经元之间连接的权重ωij呢?反向传播算法(Back Propagation)提供了解决方法。
训练的思路同样是梯度下降算法,我们定义一个损失函数L,通过朝着损失函数下降最快的方向也就是梯度方向去调整我们的权重系数。损失函数可以为均方误差:
E=21j=1∑m(y^j−yj)2
接下来的问题就是求损失函数E对需要训练的权重系数的梯度∂ωij∂E。
输出层权重训练
首先以从隐层至输出层的连接权重ωhj为例进行推导。这个求梯度的过程就是链式求导法则,首先我们分析一下ωhj是如何影响到我们的损失函数E的,ωhj首先影响了第j个输出层神经元的输入值βj,然后进而通过激励函数Sigmoid影响到其输出值y^j,然后影响到E。
这个求导过程为:
∂ωhj∂E=∂y^j∂E×∂βj∂y^j×∂ωhj∂βj
我们分别来分析这三项:
第一项:
将上面E的表达式代入∂y^j∂E:
∂y^j∂E=∂y^j∂21j=1∑m(y^j−yj)2=−(yj−y^j)
第二项:
这一项是神经元输出对输入求导,实际上就是Sigmoid求导:
∂βj∂y^j=yj(1−yj)
第三项:
这一项是神经元的输入对权重求导,实际上就等于上一个神经元的值bh:
∂ωhj∂βj=bh
所以根据梯度下降规则更新权重过程为:
ωhj←ωhj−η∂ωhj∂E
=ωji+η(yj−y^j)yj(1−yj)bh=ηδjbh
上式中的δj我们定义为:
δj=(yj−y^j)yj(1−yj)
隐层权重训练
隐层神经元权系数vih首先影响bh神经元的输入αh,进而影响输出。
∂vih∂E=∂bh∂E×∂αh∂bh×∂vih∂αh=j=1∑l∂βj∂E×∂bh∂βj×bh(1−bh)×xi
=xibh(1−bh)j=1∑lωhjδj
至此,我们求出了损失函数对输出层权重系数的梯度和对隐层权重系数的梯度,然后就可以根据梯度下降算法对我们的网络进行训练了。
反向传播算法原理比较简单,推导起来由于标号复杂显得繁琐,后面我们训练网络不怎么关心反向传播的内部求解过程,因为pytorch提供了自动求导的功能,这一点让使用者着重于自己的网络结构构建和参数调节,十分方便!!
花这么大功夫敲公式推导BP算法只是为了让读者对训练的过程有个清楚的理解,接下来在pytorch中实战一个简单的全连接网络。
Pytorch 全连接网络实现
Pytorch 上手非常容易,这里有个翻译版的60min入门:
https://www.jianshu.com/p/889dbc684622
使用的数据集为Mnist手写数字,训练集有60000个样本,测试集有10000个样本,首先我们建立一个工程并下载数据集如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
| import torch
from torchvision import datasets, transforms
if __name__ == '__main__':
train_dataset = datasets.MNIST(root='./data/', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data/', train=False, transform=transforms.ToTensor(), download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=False)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=16, shuffle=False)
for i, data in enumerate(train_loader, 0):
image, label = data
print(image.shape)
|
torch里面有MNIST数据集,所以直接调用datasets.MNIST下载就行了,然后将得到的数据集用DataLoader类装起来,这个对象参数中的batch_size为每一批的样本个数,也就是训练时一次性装载进内存的数据,shuffle是将数据集顺序打乱的操作。
这段代码的运行输出:
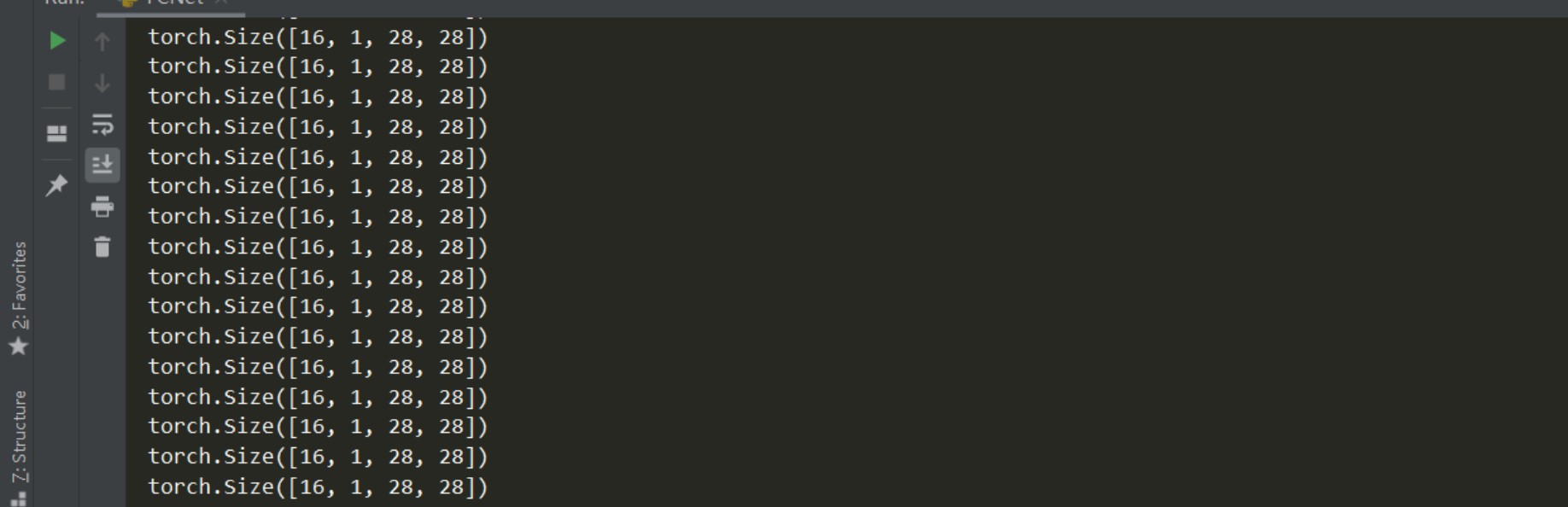
可以看到打印出的Tensor是四维的一个数组,以后我们输入神经网络的都是一个四维的Tensor,第一维为batch_size,后面三维为图像的C*W*H,也就是颜色通道数和图像的长宽。MNIST是黑白的数据集,所以颜色通道为1,对于彩色图片来说通道数为3。
装载完数据就可以进行神经网络的构建了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
| import torch
import torch.nn as nn
from torch.optim import optimizer
from torchvision import datasets, transforms
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class FCNet(nn.Module):
def __init__(self):
super(FCNet, self).__init__()
self.features = nn.Sequential(
nn.Linear(784, 100),
nn.Sigmoid(),
nn.Linear(100, 10)
)
def forward(self, x):
x = x.view(16, -1)
output = self.features(x)
return output
def train(train_loader):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
output = net(inputs)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 100 == 99:
print('%5d loss: %.3f' %
(i + 1, running_loss / 100))
running_loss = 0.0
def test(test_loader):
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on test images: %d %%' % (
100 * correct / total))
return correct / total
if __name__ == '__main__':
train_dataset = datasets.MNIST(root='./data/', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(root='./data/', train=False, transform=transforms.ToTensor(), download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=False)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=16, shuffle=False)
net = FCNet().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(20):
print('Start training: epoch {}'.format(epoch+1))
train(train_loader)
test(test_loader)
|
不熟悉pytorch建议先看看上面的教程,上手很快,这个框架也给了我们很多便利,搭建神经网络十分简单。
上述代码搭建的是一个最简单的三层的全连接网络,输入层神经元为28*28也就是每张图的像素个数,有一个隐层为100个神经元,输出层为10个神经元对应10类数字。代码注释比较详细,这里不细说。
最后训练的结果:
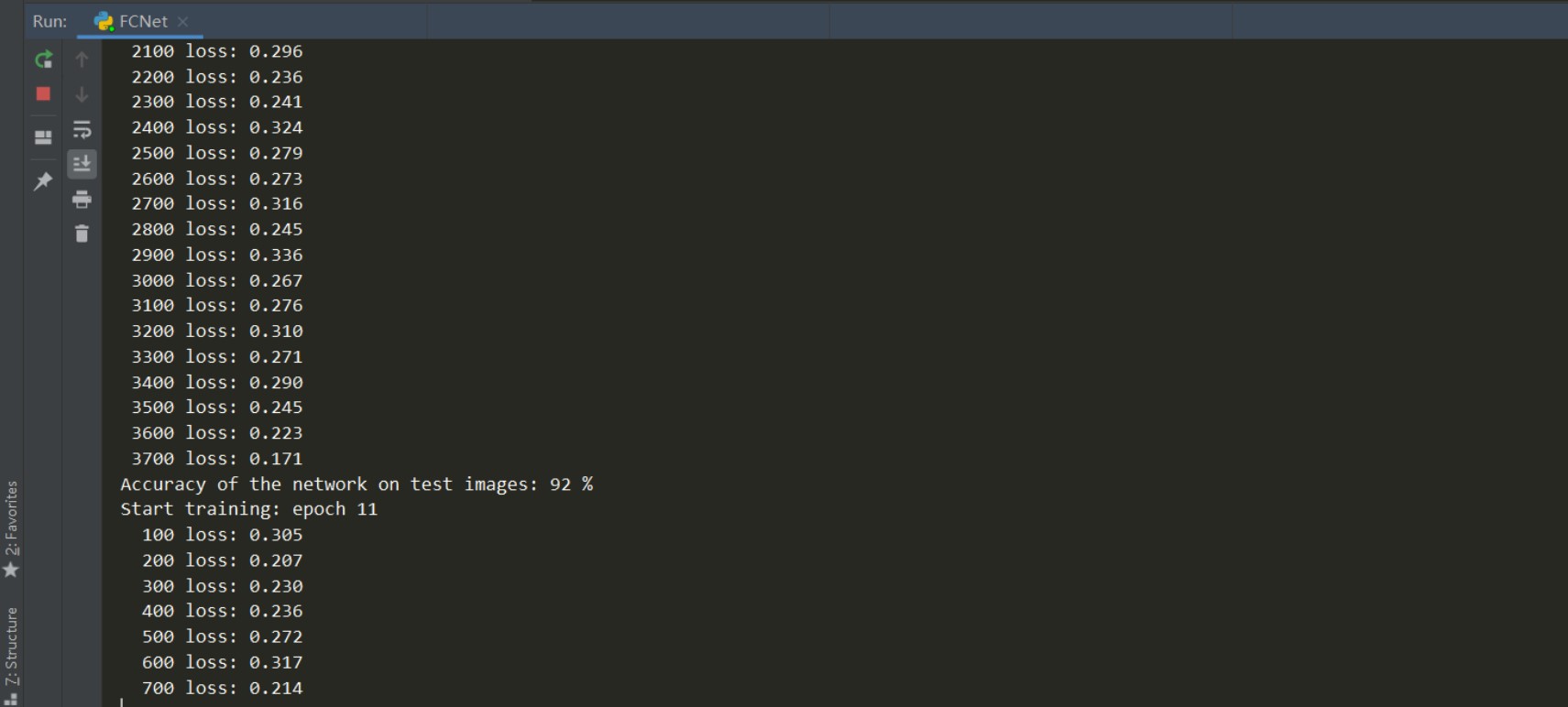
这里可以看到,经过10轮的训练之后,网络对测试集的准确率达到了0.92,这还仅仅是一个最简单的三层全连接网络!可见神经网络的强大。
这里要注意的就是,网络的训练都是前几轮损失函数值下降的很快,准确率上升也快,后面损失函数就不怎么下降了,这也意味着我们的模型正在逐渐收敛。由于网络简单且图片较小,网络的训练很快,特别是使用GPU的话。
我这里20轮训练之后,准确率达到了94%,但是一直训练下去的话会发现网络准确率不再上升,这是因为网络的结构本身比较简单,学习能力有限,之后我们会使用卷积神经网络对这个数据集进行分类,能够达到更高的准确率。
总结
本篇文章主要介绍了全连接神经网络的基本结构以及著名的反向传播算法(BP)的原理推导,最后使用pytorch实现了一个最简单的全连接神经网络对MNIST手写数据集进行分类,实例中的代码已经上传至github:https://github.com/Fanxiaodon/nn/tree/master/FCNetMnist
全连接神经网络存在一些缺陷,后面我们会提到,下篇介绍卷积神经网络CNN,CNN相比全连接网络有一些较大的优点,广泛应用于图像处理。
参考资料
- 周志华《机器学习》
- PyTorch 深度学习: 60分钟快速入门