谈谈Python大文件处理问题
前言
有最近需要对大的文本文件(日志文件,1GB以上)进行逐行的分析处理,考虑到实现的便利,这里使用Python脚本实现,这里的文本文件使用 utf-8 编码。最开始为了快速实现功能,采用readlines()方法一次性将日志读入内存进行处理,由于日志都放在内存中,后续的处理上效率也比较高。
随着需要处理的日志文件的大小增大,上述方法变得不可行(占用大量内存),于是不得不采用部分读入处理的方式。一个最基本的思路是分块(或者逐行)读入日志进行分析,对于重要的日志行的文件偏移进行记录,便于后面重新打开文件并快速访问到这部分日志。
相关方法
使用大小为 2.2 GB 的文本文件进行实验,使用我的笔记本电脑测试,相关硬件如下:
- CPU 为 Ryzen 7 5800H
- 磁盘为 1TB Sumsung 980
- 内存为 16GB 3200MHz板载内存,应该也不是性能瓶颈
一次性读入
调用readlines()方法将日志文件一次性读入内存中,相关代码片段如下:
1 | path = './2023-07-28/2023-07-28.log' |
测试结果如下:

可以看到占用了近 5GB 的内存!之所以一个 2.2 GB 的文本文件能够占用这么大的内存,主要是以下原因:将每行保存为一个字符串对象,字符串对于每个字符占用的字节数要大于文本编码的(为了支持随机访问里面的某个字符,字符会设计成等大小存储,这样一个ASCII字符可能会占用2个甚至3个字节),而且需要保存字符串额外的信息(如字符串的长度之类,这取决于Python字符串对象设计)。
总之,这么大的内存占用量是不可接受的。
逐行读取(方式一)
通过readline方法进行逐行读取,代码如下:
1 | path = './2023-07-28/2023-07-28.log' |

处理时间上和一次性读入内存相似,由于读取完当前行立马就释放掉了,因此占用极少的内存。通常情况下需要做文件行与行之间的关联操作,也就是需要回看之前的行,这时可以调用f.tell()来获取文件当前的偏移,然后使用f.seek(offset)将文件指针移到之前记录的位置。
这里需要注意的是,在使用'r'模式读取文件时,在循环中频繁使用f.tell()调用十分耗时,如果简单的在上述循环中加一行调用offset = f.tell(),对于上述大文件,在几分钟之内都无法读取完成文件,为了测试实际耗时情况,每读取 10000 行文件之后,打印一下时间戳:
1 | line_num = 0 |
运行结果如下:
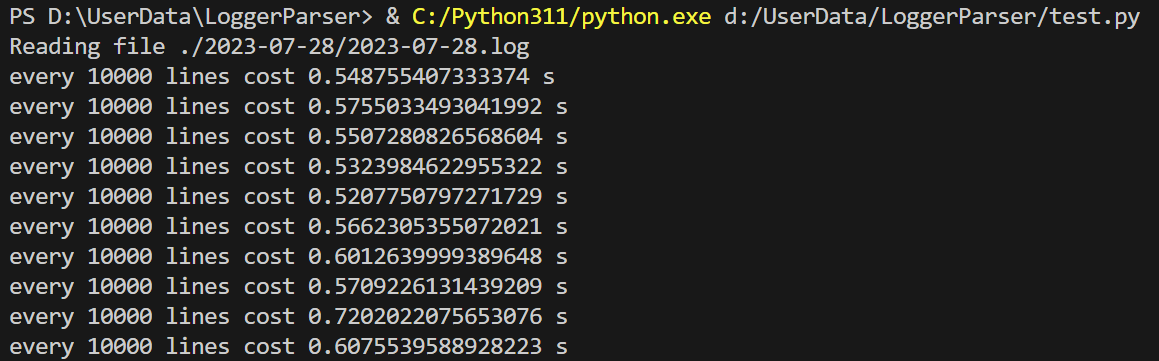
平均每 10000 行需要 0.6 s左右,整个上述 2.2GB 日志文件共有 22917621 行,预计处理耗时达到 1375 s,也就是 22.9 min!!
解决这个问题的方法是使用二进制方式读取文件,也就是'rb'模式读取,在读取文件的时候不对文件进行解码,而是将一行的字节读取出来之后手动调用字符串的解码函数line.decode(encoding='utf-8):
1 | path = './2023-07-28/2023-07-28.log' |
执行结果:

可以看到,效率大大提高,这里的原因估计是因为采用指定解码方式打开文件时调用f.tell()没法简单将当前文件指针直接返回,而是要进行部分计算,而使用二进制方式读取文件,文件内容以字节数组的形式返回,偏移量可以较为简单的得到。
虽然相较于不调用f.tell()时耗时(以二进制方式读取再手动解码也只需要 9 s左右)要慢的多,但这个结果相较于上述使用文本方式读取的结果是很可以被接受的。考虑到实际使用时并不会将每行的偏移量都记录下来,调用f.tell()的时候会更少。
逐行读取(方式二)
一个打开的文件对象本身是可迭代的,通过 for 循环对齐进行迭代能够得到文件中的每一行:
1 | path = './2023-07-28/2023-07-28.log' |
实际的时间和readline方式很相近:

当尝试在循环过程中调用f.tell()获取当前的文件偏移时:
1 | for i, line in enumerate(f): |
会得到一个运行时错误:
1 | OSError: telling position disabled by next() call |
当我们通过 for 循环迭代 f 对象的时候实际上是隐式的调用了其__iter__()方法获取一个可迭代对象,然后调用该可迭代对象的__next__()方法,而报错的含义是在next()方法中禁用了tell()调用,也就是说使用 for 循环迭代 f 对象时候是不能够获取当前文件指针位置的。
这里实际上也就是类库实现者考虑到效率问题(上面我们测试发现真的很慢!),直接就将f.tell()调用给禁止了。那是不是我们使用这种方式对文件逐行访问的时候就没有办法获取到当前读取得到的文件位置了呢?其实不是的,next()方法禁用tell()调用只发生在以'r'方式(也就是文本方式读取)打开文件的时候,在二进制方式读取的时候仍然是可用的。这样我们就不难写出和使用readline()方法逐行读取相似的代码了:
1 | path = './2023-07-28/2023-07-28.log' |
执行效率也和上面的方法类似:

同样,实际情况下我们不会每行都调用f.tell()来获取当前位置,因此实际处理文件的时间会大大缩短。
总结
我们经常会有按行处理文件的需求,通常最简单的方式是一次性将文件读入内存然后进行处理,这种方式较为简单且处理效率较高,但是对内存占用往往比较大,因此只适用于小文件处理。
本文对大文件(2.2GB日志文件),通过Python脚本分别使用一次性读入内存(通过readlines()方法)以及两种逐行读入方式进行处理,并进行了相关的效率分析。实际上,从单纯的将文件读入内存的过程来看,一次性读入方法和逐行读入方式效率差不多,但主要是逐行读入时无法直接回看之前读入的行,因此需要调用tell()来获取并记录相应的文件偏移。
而测试过程发现,通过文本形式读入文件并调用tell()时非常耗时,且使用文本形式读入文件且使用 for 循环迭代文件 f 时,在循环内部tell()调用被禁用了。一个更有效的方式也是我最后采用的形式是,通过二进制形式读入文件(打开文件时使用'rb'选项),然后手动对都进来的字节进行编码,这样频繁调用tell()时效率要高得多。