机器级解释函数调用过程
引言
最近想抽出时间好好读一读CSAPP,这本书很早就买了,但一直没有时间去通读一遍。这本书主要是讲计算机系统中的一些底层知识,内容涉及比较广,包括了计算机组成、操作系统、程序编译、链接等很多内容,和之前看过的很多书有重合部分。本篇文章主要介绍如何从汇编码(机器级)的角度去看待程序的执行,尤其是介绍函数调用过程运行时栈发生的变化,本文的大部分内容,包括示例来自于书中的第3章。
x86-64 汇编
Intel系列处理器通常称为x86,目前常用的笔记本或台式机都是 64 位的处理器,这些处理器使用的机器语言一般都是 x86-64,我记得以前学习微机原理课的时候,学习的还是8086处理器上的汇编。8086是Intel的第一代16位的处理器,只有8个16位的寄存器,而现在的64位处理器对其进行了扩展,共有16个64位的寄存器。
需要注意的是,这里采用的汇编代码是ATT格式的,与Intel格式的汇编码有些不同:
- Intel汇编码省略了指示大小的后缀,如ATT格式中的
pushq,在Intel中为push - Intel代码访问寄存器时省略了
%,如ATT格式是%rbx,在Intel中为rbx - ATT代码使用小括号
()来访问内存中的位置,而Intel代码使用中括号[] - 操作数的顺序不同,如ATT中
movq %rax, %rbx,第一个操作数为源操作数,第二个为目的操作数,Intel格式正好相反。
64位处理器中 16 个寄存器对理解 x86-64 汇编十分重要,见下图(图源 CSAPP):
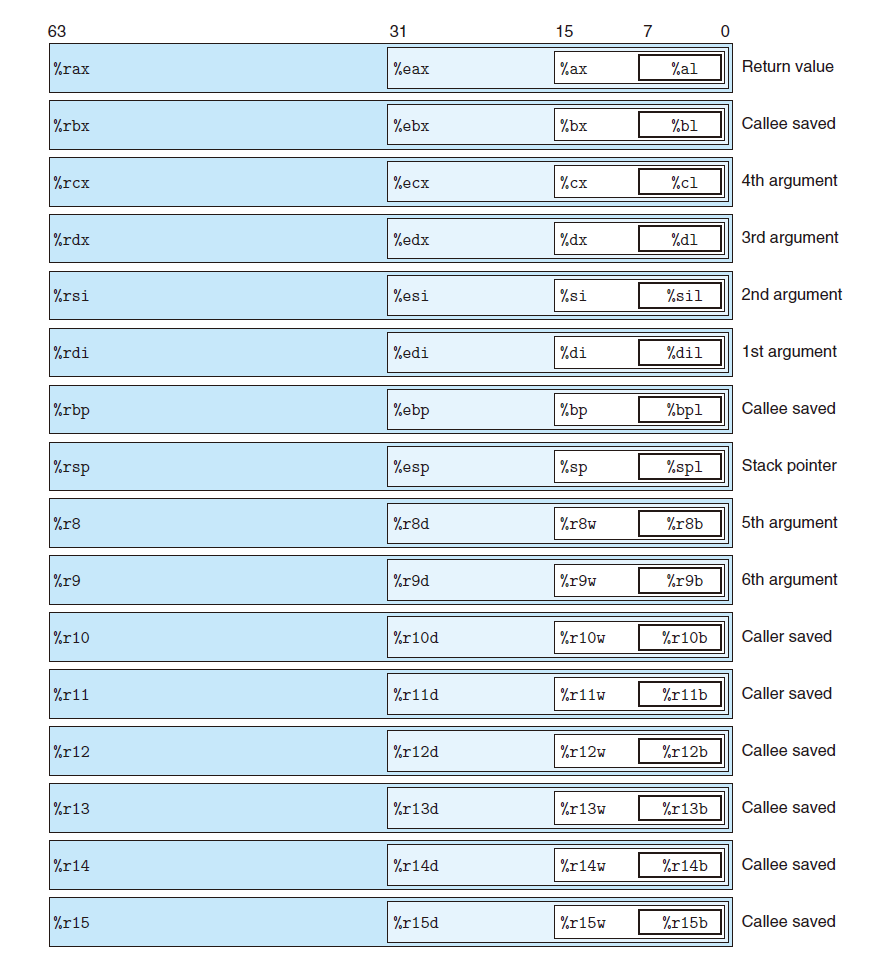
可以看出来,实际上最早的8086汇编就是前8个寄存器的最右边的16位,换句话说,这16个寄存器就是在之前处理器的基础上一步步扩展出来的。这些寄存器在程序执行过程中有着不同的角色,如栈指针%rsp维护着内存中栈顶的地址,可以通过这个指针或者添加偏移量来读取运行时栈中的内容。又如,在函数调用的时候,函数参数一般是通过寄存器进行传递,第一个参数通过%rdi寄存器传递进来。实际上这些寄存器的使用十分灵活,可以用来保存临时变量等。
需要注意的是,对CPU寄存器中的变量的访问速度会远快于对内存中变量的访问速度(约100倍),主要原因是寄存器离算术逻辑单元(ALU)更近,不需要通过总线访问。这遵循着存储器中的定律:空间越小的存储器,访问速度越快。
具体的x86-64的语法这里就不介绍了,和8086处理器的比较相似,对于一般的计算机如何进行算术逻辑运算、运行流程控制等都不准备介绍。本篇文章主要是想介绍函数调用过程运行时栈发生的变化。
函数调用
运行时栈
考虑C语言中的函数调用问题,当在一个程序中调用另一个程序的时候,如在函数P中调用函数Q,至少需要做以下几件事情:首先需要将程序计数器指针指向Q的起始地址,在Q函数返回的时候需要将程序计数器指向P中函数Q后面的那条指令;其次需要完成函数参数传递问题,以及函数返回值的传递问题;最后是函数Q运行时可能需要保存额外的局部变量。
为了解决上述的问题,C语言调用时采用「运行时栈」来对函数的调用过程进行维护:
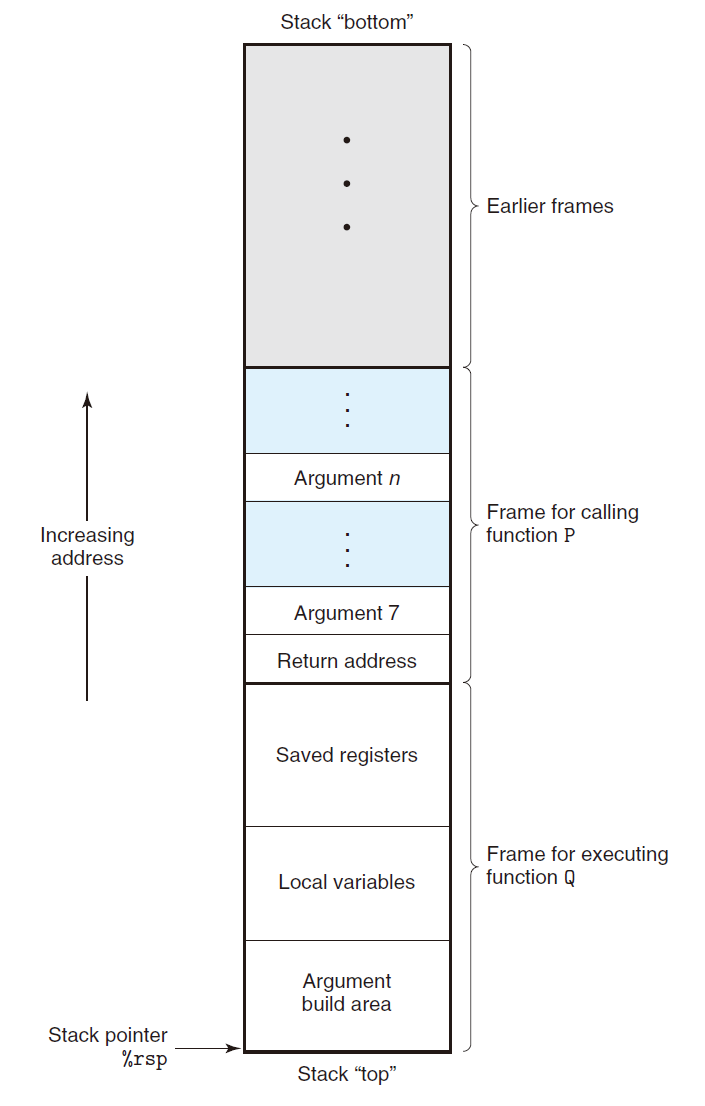
需要注意这里的栈是倒着画的,栈顶在下面,栈顶的内存地址是更小的,换句话说栈增长的方向是内存地址减小的方向。
从上面图中我们可以看出,在函数P调用Q时,首先在函数P的「栈帧」压入了返回地址,指示函数Q执行完成之后的断点位置。然后函数Q执行的时候会开辟它自己的栈帧(实际上就是将栈顶指针%rsp减小),并可能会做以下几件事情:
- 将一些必要的寄存器的值进行保存(这些寄存器称为被调用者保存的寄存器(Callee saved),也就是函数Q有义务保证自己运行前后这些寄存器的值是保持不变的,因此函数P可以放心的将变量存储在这些寄存器中。)
- 保存Q中的一些局部变量。
- 若Q需要调用其它函数,且该函数的参数大于6个,则在Q的栈帧中存储这些参数的值。(后面会有示例)
例子
下面举几个例子来说明函数调用过程中的参数传递问题以及局部变量和寄存器存储问题。
- 函数参数传递
一个函数调用另一个函数,可能会携带参数或产生返回值,这些数据一般来说通过寄存器进行传递,可以看看本文第一张图中的共有%rdi, %rsi, %rdx, %rcx, %r8, %r9六个寄存器用于参数传递,%rax用于存放函数的返回值。
当函数参数个数小于等于6时,通过寄存器就能够实现传参,当参数个数大于6时,会将多出来的参数放在调用者的运行时栈中。或者换句话说,调用者先在自己的栈中构造好多出的参数,然后再调用函数。
例如下面这个带有 8 个参数的函数:proc.c
1 | void proc(long a1, long *a1p, |
我们对其进行编译(-Og选项是为了取消编译器的优化,这样更好的看出汇编代码的结构):
1 | gcc -Og -S proc.c |
得到汇编码的关键片段如下(标出了参数传递过程,以及添加了部分注释):
1 | void proc(a1, a1p, a2, a2p, a3, a3p, a4, a4p) |
可以看到函数proc传入的8个参数中,前6个参数就是通过之前所说的6个寄存器进行传递的,后面两个参数是从%rsp+8和%rsp+16两个指针指向的内存处取得:
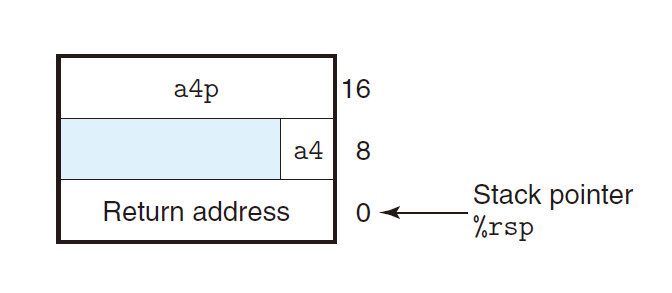
也就是说,在调用函数proc之前,需要在运行时栈中构建好这两个参数。
- 栈上的局部变量存储
局部变量可以存放在寄存器中,在寄存器不足存放所有本地数据时可以在自己的栈帧中存放;此外当需要对局部变量取地址时,必须将其放在内存中(放在自己的栈帧中)。
考虑以下调用过程,swap_add函数需要两个地址参数,因此调用者caller需要将在自己的运行时栈上存储参数,这样才能产生地址。
1 | long swap_add(long *xp, long *yp) |
将其汇编得到关键的片段如下:
1 | swap_add: |
这里我机器上编译得到的结果和书本上的有所差别,书上是在栈上分配了16字节的空间刚好用于存放两个局部变量,我这边是分配了32字节,用了16字节存放局部变量。但这也能够说明栈上的局部变量存储问题。
- 寄存器中的局部存储
寄存器中的空间是被所有过程共享的资源,仔细看第一张寄存器的图可以发现,%rbx, %rbp和%r12~%r15都是被调用者保存的寄存器(Callee saved),意味着当过程P调用过程Q时,过程Q有义务保证这些寄存器的值和调用前一致,也就是说P可以放心的将变量存放到这些寄存器中,不担心值被破坏。
对于Q而言,要保证某个寄存器值不变,要么就根本不去操作这个寄存器,要么就先将原始的值压入栈中,在最后返回前将其出栈恢复。实际上对于上面的例子,我们就能看到在 caller 函数的最开始将%rbp寄存器入栈,在函数返回前又将这个寄存器出栈。
除了被调用者保存的寄存器(Callee saved),其余都是调用者保存的寄存器(Caller saved),也就是说任何函数都能够修改它们,调用者不能假定放在里面的数据不被破坏。
考虑下面的程序,程序P两次调用Q,第一次调用前需要先保存参数x的值后续使用,调用之后还需要保存第一次调用的结果。
1 | long Q(long x); |
汇编代码的关键片段(为方便阅读,删除了部分伪指令便于阅读):
1 | P: |
参考文献
- 深入理解计算机系统(CSAPP 3th)