前言
本篇博客是 6.S081课程的第五次Lab:Copy-on-Write Fork for xv6 的分析,这次Lab我认为还是比较有难度的,内容是实现fork时的写时复制,我们都知道fork系统调用创建一个新的子进程,这个子进程是父进程的复制,其地址空间和父进程完全一致,这意味着需要在fork时将父进程的页表复制一份,且将有效页表项指向的物理内存中的内容复制一遍,这是比较耗时的。
现代操作系统普遍实现了fork的写时复制,也就是fork系统调用时,只是将父进程的页表复制一份,并不真正复制物理内存中的内容,fork调用之后父子进程的相同虚拟地址对应同一物理页面,因此需要将所有的PTE标记为只读。当父子进程中某一个进程对这些页面写数据时,将会触发页面错误(Page Fault),我们在处理页面错误时再分配相应的物理页面并改变相应的PTE。fork后的示意图如下:
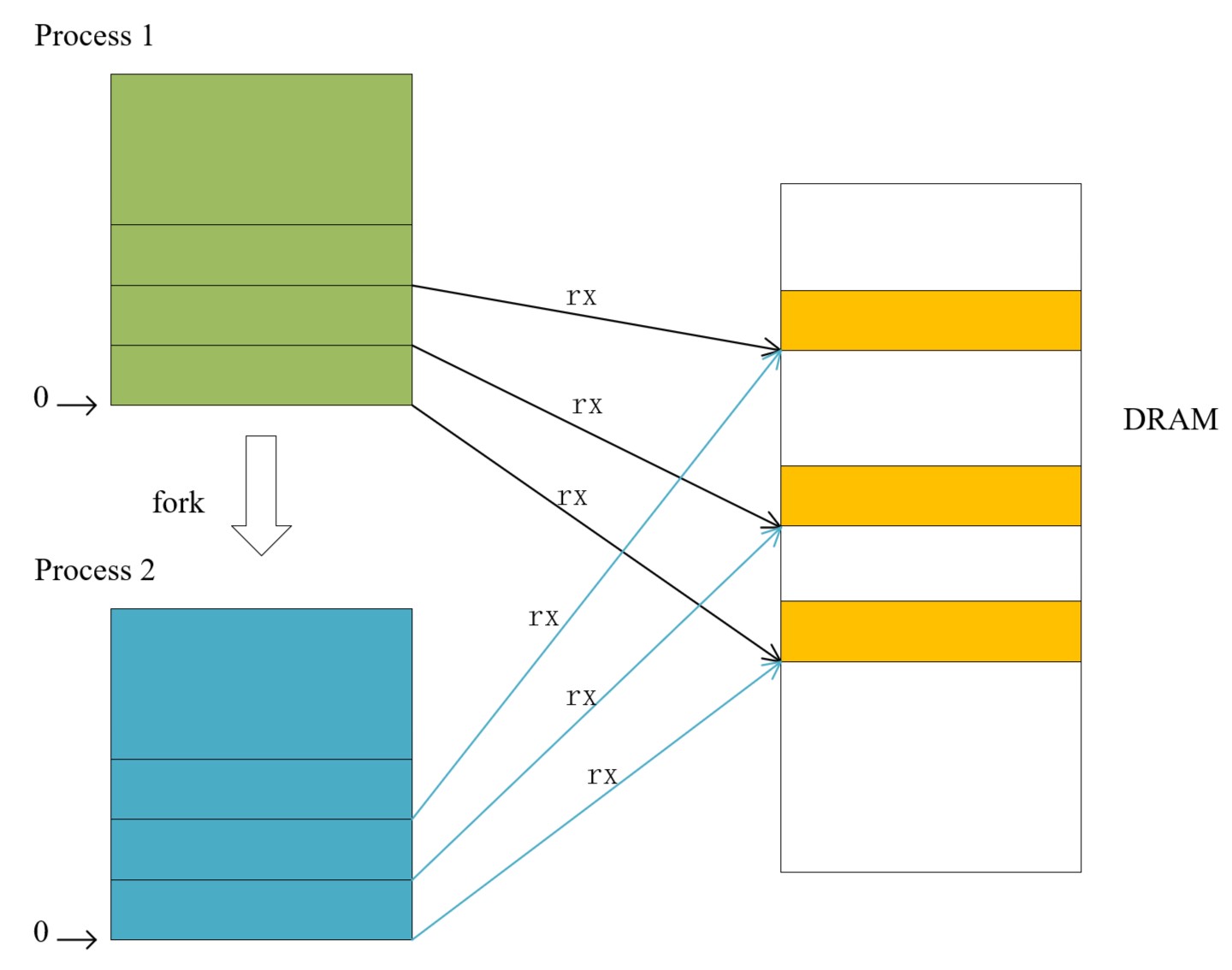
实际上,fork写时复制是一种优化手段,它将内存页面的复制推迟到了触发页面错误(Page Fault)的时候,由于内存中存在大量页面存放只读数据(常量,代码段等),实际上很多页面可以被多个进程复用,因此写时复制会极大的提高效率。
Implement copy-on write
首先,为了区分一个物理页面是否是copy-on write页面,我们在kernel/riscv.h中添加一个PTE标志:
1
| #define PTE_COW (1L << 8)
|
由于写时复制机制存在,每一个物理页面可能会被多个不同的进程页表引用,这对物理页面销毁提出了挑战,我们不能单纯的在进程销毁的时候就将物理页面回收,因为可能还有其他的进程在引用这个页面。解决的方法是对每个物理页面进行引用计数,只有当页面的引用计数为 0 是才将页面回收。
由于所有的物理内存管理是在kernel/kalloc.c中实现,我们在其中添加,:
1
| uint8 page_count[PHYSTOP / PGSIZE + 1];
|
对于多核CPU,修改页面引用计数时可能存在竞争,因此需要加锁,加入函数:
1
2
3
4
5
6
7
8
|
void
incref(uint64 pa) {
int pn = pa / PGSIZE;
acquire(&kmem.lock);
page_count[pn]++;
release(&kmem.lock);
}
|
在每次分配页面的时候,我们将分配的页面的引用数置为1:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| void *
kalloc(void)
{
struct run *r;
acquire(&kmem.lock);
r = kmem.freelist;
if(r) {
kmem.freelist = r->next;
page_count[(uint64)r / PGSIZE] = 1;
}
release(&kmem.lock);
if(r) {
memset((char*)r, 5, PGSIZE);
}
return (void*)r;
}
|
在每次调用kfree的时候将引用计数 -1,只有引用计数为 0时才释放页面:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| void
kfree(void *pa)
{
acquire(&kmem.lock);
int pn = (uint64)pa / PGSIZE;
page_count[pn] --;
if (page_count[pn] > 0) {
release(&kmem.lock);
return;
}
release(&kmem.lock);
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
acquire(&kmem.lock);
r->next = kmem.freelist;
kmem.freelist = r;
release(&kmem.lock);
}
|
由于内核最开始获取内存的部分并没有调用kalloc,为了保证页面引用数的正确性,需要在freerange函数中将每个页面引用数置为 1:
1
2
3
4
5
6
7
8
9
10
| void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE) {
page_count[(uint64)p / PGSIZE] = 1;
kfree(p);
}
}
|
这样,我们只要维护好页面的引用计数就行了。现在我们实现fork的写时复制,首先,需要修改kernel/vm.c中的uvmvopy函数,这个函数是每次fork调用时会调用的函数,用于子进程复制父进程的相关内容,我们删掉物理页面复制的语句,只是单纯的复制父进程的页表,并将父子页表项(PTE)的写权限去除,并标记为写时复制页(加上PTE_COW标记),将子进程的PTE和父进程指向相同的物理页面。最后不要忘记增加物理页面的引用计数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| int
uvmcopy(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
pa = PTE2PA(*pte);
*pte = *pte & (~PTE_W);
*pte = *pte | PTE_COW;
flags = PTE_FLAGS(*pte);
if(mappages(new, i, PGSIZE, pa, flags) != 0){
goto err;
}
incref(pa);
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
|
这样处理之后,由于PTE都被去除了写权限,无论是父进程还是子进程对他们的地址空间执行写动作时都会触发页面错误(Page Fault),我们只需要处理好Page Fault就行了,修改kernel/trap.c中的usertrap函数,判断页面写错误(sscause寄存器值为15,查手册可知),stval寄存器中保存了触发页面错误的虚拟地址,调用cowfault函数处理:
1
2
3
4
5
6
7
8
| else if (r_scause() == 15) {
struct proc* p = myproc();
if (cowfault(p->pagetable, r_stval()) < 0) {
p->killed = 1;
exit(-1);
}
}
|
cowfault实现如下,首先判断不合法虚拟地址(在测试中会有,不写过不了测试,会引发panic walk),然后我们判断页面是不是PTE_COW页面,如果不是就杀死进程。然后需要判断当前物理页面引用数是否大于等于2,只有超过两个引用时,分为一个新的物理页面并复制原页面的内容,然后将当前进程的PTE恢复写权限并修正至分配的物理页面;如果引用计数为1,则不需要分配新的物理页面,而只是恢复页面的写权限即可:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| int cowfault(pagetable_t pagetable, uint64 rval) {
if (rval >= MAXVA) {
return -1;
}
pte_t* pte = walk(pagetable, rval, 0);
if (pte == 0 || !(*pte & PTE_COW)) {
printf("not cow page\n");
return -1;
}
if(page_count[PTE2PA(*pte)/PGSIZE] >= 2) {
page_count[PTE2PA(*pte)/PGSIZE] --;
char* mem;
if ((mem = kalloc()) == 0) {
return -1;
}
memmove(mem, (char*)PTE2PA(*pte), PGSIZE);
uint flag = PTE_FLAGS(*pte) | PTE_W;
flag = flag & (~PTE_COW);
(*pte) = PA2PTE((uint64)mem) | flag;
} else {
(*pte) |= PTE_W;
(*pte) &= (~PTE_COW);
}
return 0;
}
|
最后还要修改kernel/vm.c中的copyout函数,基本逻辑和处理页面错误类似,当复制的目的地址(dstva)指向的页面是COW页面时调用cowfault函数处理:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva);
if (va0 >= MAXVA)
return -1;
pte_t* pte = walk(pagetable, va0, 0);
if (pte == 0 || (*pte & PTE_V) == 0 || (*pte & PTE_U) == 0)
return -1;
if (*pte & PTE_COW) {
if (cowfault(pagetable, va0) < 0) {
printf("cowfault < 0\n");
return -1;
}
}
pa0 = PTE2PA(*pte);
n = PGSIZE - (dstva - va0);
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}
|
最后在kernel/def.h中加上cowfault和incref的声明:
1
2
| void incref(uint64 pa);
int cowfault(pagetable_t pagetable, uint64 rval);
|
测试结果
2022/6/20测试通过:

参考文献
- https://pdos.csail.mit.edu/6.828/2021/schedule.html